Analysis of variance
In statistics, analysis of variance (ANOVA) is a collection of statistical models, and their associated procedures, in which the observed variance in a particular variable is partitioned into components attributable to different sources of variation. In its simplest form ANOVA provides a statistical test of whether or not the means of several groups are all equal, and therefore generalizes t-test to more than two groups. Doing multiple two-sample t-tests would result in an increased chance of committing a type I error. For this reason, ANOVAs are useful in comparing two, three or more means.
Contents |
Models
There are three classes of models used in the analysis of variance, and these are outlined here.
Fixed-effects models (Model 1)
The fixed-effects model of analysis of variance applies to situations in which the experimenter applies one or more treatments to the subjects of the experiment to see if the response variable values change. This allows the experimenter to estimate the ranges of response variable values that the treatment would generate in the population as a whole.
Random-effects models (Model 2)
Random effects models are used when the treatments are not fixed. This occurs when the various factor levels are sampled from a larger population. Because the levels themselves are random variables, some assumptions and the method of contrasting the treatments differ from ANOVA model 1.
Mixed-effects models (Model 3)
A mixed-effects model contains experimental factors of both fixed and random-effects types, with appropriately different interpretations and analysis for the two types.
Assumptions of ANOVA
The analysis of variance has been studied from several approaches, the most common of which use a linear model that relates the response to the treatments and blocks. Even when the statistical model is nonlinear, it can be approximated by a linear model for which an analysis of variance may be appropriate.
A model often presented in textbooks
Many textbooks present the analysis of variance in terms of a linear model, which makes the following assumptions about the probability distribution of the responses:
- Independence of cases – this is an assumption of the model that simplifies the statistical analysis.
- Normality – the distributions of the residuals are normal.
- Equality (or "homogeneity") of variances, called homoscedasticity — the variance of data in groups should be the same. Model-based approaches usually assume that the variance is constant. The constant-variance property also appears in the randomization (design-based) analysis of randomized experiments, where it is a necessary consequence of the randomized design and the assumption of unit treatment additivity.[1] If the responses of a randomized balanced experiment fail to have constant variance, then the assumption of unit treatment additivity is necessarily violated.
To test the hypothesis that all treatments have exactly the same effect, the F-test's p-values closely approximate the permutation test's p-values: The approximation is particularly close when the design is balanced.[2] Such permutation tests characterize tests with maximum power against all alternative hypotheses, as observed by Rosenbaum.[nb 1] The anova F–test (of the null-hypothesis that all treatments have exactly the same effect) is recommended as a practical test, because of its robustness against many alternative distributions.[3][nb 2] The Kruskal–Wallis test is a nonparametric alternative that does not rely on an assumption of normality. And the Friedman test is the nonparametric alternative for a one-way repeated measures ANOVA.
The separate assumptions of the textbook model imply that the errors are independently, identically, and normally distributed for fixed effects models, that is, that the errors (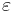 's) are independent and
's) are independent and
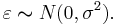
Randomization-based analysis
In a randomized controlled experiment, the treatments are randomly assigned to experimental units, following the experimental protocol. This randomization is objective and declared before the experiment is carried out. The objective random-assignment is used to test the significance of the null hypothesis, following the ideas of C. S. Peirce and Ronald A. Fisher. This design-based analysis was discussed and developed by Francis J. Anscombe at Rothamsted Experimental Station and by Oscar Kempthorne at Iowa State University.[4] Kempthorne and his students make an assumption of unit treatment additivity, which is discussed in the books of Kempthorne and David R. Cox.
Unit-treatment additivity
In its simplest form, the assumption of unit-treatment additivity states that the observed response 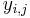 from experimental unit
from experimental unit  when receiving treatment
when receiving treatment 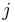 can be written as the sum of the unit's response
can be written as the sum of the unit's response 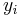 and the treatment-effect
and the treatment-effect 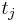 , that is [5][6]
, that is [5][6]
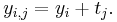
The assumption of unit-treatment addivity implies that, for every treatment , the th treatment have exactly the same effect on every experiment unit.
The assumption of unit treatment additivity usually cannot be directly falsified, according to Cox and Kempthorne. However, many consequences of treatment-unit additivity can be falsified. For a randomized experiment, the assumption of unit-treatment additivity implies that the variance is constant for all treatments. Therefore, by contraposition, a necessary condition for unit-treatment additivity is that the variance is constant.
The property of unit-treatment additivity is not invariant under a "change of scale", so statisticians often use transformations to achieve unit-treatment additivity. If the response variable is expected to follow a parametric family of probability distributions, then the statistician may specify (in the protocol for the experiment or observational study) that the responses be transformed to stabilize the variance.[7] Also, a statistician may specify that logarithmic transforms be applied to the responses, which are believed to follow a multiplicative model.[8][9] According to Cauchy's functional equation theorem, the logarithm is the only continuous transformation that transforms real multiplication to addition.
The assumption of unit-treatment additivity was enunciated in experimental design by Kempthorne and Cox. Kempthorne's use of unit treatment additivity and randomization is similar to the design-based inference that is standard in finite-population survey sampling.
Derived linear model
Kempthorne uses the randomization-distribution and the assumption of unit treatment additivity to produce a derived linear model, very similar to the textbook model discussed previously.
The test statistics of this derived linear model are closely approximated by the test statistics of an appropriate normal linear model, according to approximation theorems and simulation studies by Kempthorne and his students (Hinkelmann and Kempthorne 2008). However, there are differences. For example, the randomization-based analysis results in a small but (strictly) negative correlation between the observations.[10][11] In the randomization-based analysis, there is no assumption of a normal distribution and certainly no assumption of independence. On the contrary, the observations are dependent!
The randomization-based analysis has the disadvantage that its exposition involves tedious algebra and extensive time. Since the randomization-based analysis is complicated and is closely approximated by the approach using a normal linear model, most teachers emphasize the normal linear model approach. Few statisticians object to model-based analysis of balanced randomized experiments.
Statistical models for observational data
However, when applied to data from non-randomized experiments or observational studies, model-based analysis lacks the warrant of randomization. For observational data, the derivation of confidence intervals must use subjective models, as emphasized by Ronald A. Fisher and his followers. In practice, the estimates of treatment-effects from observational studies generally are often inconsistent. In practice, "statistical models" and observational data are useful for suggesting hypotheses that should be treated very cautiously by the public.[12]
Logic of ANOVA
Partitioning of the sum of squares
The fundamental technique is a partitioning of the total sum of squares S into components related to the effects used in the model. For example, we show the model for a simplified ANOVA with one type of treatment at different levels.
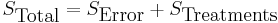
So, the number of degrees of freedom f can be partitioned in a similar way and specifies the chi-squared distribution which describes the associated sums of squares.
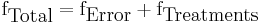
See also Lack-of-fit sum of squares.
The F-test
The F-test is used for comparisons of the components of the total deviation. For example, in one-way, or single-factor ANOVA, statistical significance is tested for by comparing the F test statistic
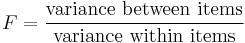
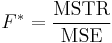
where
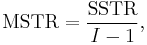 I = number of treatments
I = number of treatments
and
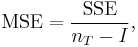 nT = total number of cases
nT = total number of cases
to the F-distribution with I − 1,nT − I degrees of freedom. Using the F-distribution is a natural candidate because the test statistic is the ratio of two scaled sums of squares each of which follows a scaled chi-squared distribution.
Power analysis
Power analysis is often applied in the context of ANOVA in order to assess the probability of successfully rejecting the null hypothesis if we assume a certain ANOVA design, effect size in the population, sample size and alpha level. Power analysis can assist in study design by determining what sample size would be required in order to have a reasonable chance of rejecting the null hypothesis when the alternative hypothesis is true.
Effect size
Several standardized measures of effect gauge the strength of the association between a predictor (or set of predictors) and the dependent variable. Effect-size estimates facilitate the comparison of findings in studies and across disciplines. Common effect size estimates reported in univariate-response anova and multivariate-response manova include the following: eta-squared, partial eta-squared, omega, and intercorrelation.
η2 ( eta-squared ): Eta-squared describes the ratio of variance explained in the dependent variable by a predictor while controlling for other predictors. Eta-squared is a biased estimator of the variance explained by the model in the population (it estimates only the effect size in the sample). On average it overestimates the variance explained in the population. As the sample size gets larger the amount of bias gets smaller,
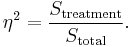
Partial η2 (Partial eta-squared): Partial eta-squared describes the "proportion of total variation attributable to the factor, partialling out (excluding) other factors from the total nonerror variation".[13] Partial eta squared is often higher than eta squared,
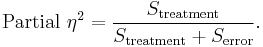
Cohen (1992) suggests effect sizes for various indexes, including ƒ (where 0.1 is a small effect, 0.25 is a medium effect and 0.4 is a large effect). He also offers a conversion table (see Cohen, 1988, p. 283) for eta squared (η2) where 0.0099 constitutes a small effect, 0.0588 a medium effect and 0.1379 a large effect. Though, considering that η2 are comparable to r2 when df of the numerator equals 1 (both measures' proportion of variance accounted for), these guidelines may overestimate the size of the effect. If going by the r guidelines (0.1 is a small effect, 0.3 a medium effect and 0.5 a large effect) then the equivalent guidelines for eta-squared would be the square of these, i.e. 0.01 is a small effect, 0.09 a medium effect and 0.25 a large effect, and these should also be applicable to eta-squared. When the df of the numerator exceeds 1, eta-squared is comparable to R-squared.[14]
Omega2 ( omega-squared ): A more unbiased estimator of the variance explained in the population is omega-squared[15][16][17]
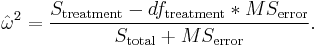
While this form of the formula is limited to between-subjects analysis with equal sample sizes in all cells,[17] a generalized form of the estimator has been published for between-subjects and within-subjects analysis, repeated measure, mixed design, and randomized block design experiments.[18] In addition, methods to calculate partial Omega2 for individual factors and combined factors in designs with up to three independent variables have been published.[18]
Cohen's ƒ2: This measure of effect size represents the square root of variance explained over variance not explained.
SMCV or standardized mean of a contrast variable: This effect size is the ratio of mean to standard deviation of a contrast variable for contrast analysis in ANOVA. It may provide a probabilistic interpretation to various effect sizes in contrast analysis.[19]
Follow up tests
A statistically significant effect in ANOVA is often followed up with one or more different follow-up tests. This can be done in order to assess which groups are different from which other groups or to test various other focused hypotheses. Follow-up tests are often distinguished in terms of whether they are planned (a priori) or post hoc. Planned tests are determined before looking at the data and post hoc tests are performed after looking at the data. Post hoc tests such as Tukey's range test most commonly compare every group mean with every other group mean and typically incorporate some method of controlling for Type I errors. Comparisons, which are most commonly planned, can be either simple or compound. Simple comparisons compare one group mean with one other group mean. Compound comparisons typically compare two sets of groups means where one set has two or more groups (e.g., compare average group means of group A, B and C with group D). Comparisons can also look at tests of trend, such as linear and quadratic relationships, when the independent variable involves ordered levels.
Study designs and ANOVAs
There are several types of ANOVA. Many statisticians base ANOVA on the design of the experiment, especially on the protocol that specifies the random assignment of treatments to subjects; the protocol's description of the assignment mechanism should include a specification of the structure of the treatments and of any blocking. It is also common to apply ANOVA to observational data using an appropriate statistical model.
Some popular designs use the following types of ANOVA:
- One-way ANOVA is used to test for differences among two or more independent groups (means),e.g. different levels of urea application in a crop. Typically, however, the one-way ANOVA is used to test for differences among at least three groups, since the two-group case can be covered by a t-test.[20] When there are only two means to compare, the t-test and the ANOVA F-test are equivalent; the relation between ANOVA and t is given by F = t2.
- Factorial ANOVA is used when the experimenter wants to study the interaction effects among the treatments.
- Repeated measures ANOVA is used when the same subjects are used for each treatment (e.g., in a longitudinal study).
- Multivariate analysis of variance (MANOVA) is used when there is more than one response variable.
History
The analysis of variance was used informally by researchers in the 1800s using least squares. In physics and psychology, researchers included a term for the operator-effect, the influence of a particular person on measurements, according to Stephen Stigler's histories.
Sir Ronald Fisher proposed a formal analysis of variance in a 1918 article The Correlation Between Relatives on the Supposition of Mendelian Inheritance.[21] His first application of the analysis of variance was published in 1921.[22] Analysis of variance became widely known after being included in Fisher's 1925 book Statistical Methods for Research Workers.
See also
Footnotes
- ^ Rosenbaum (2002, page 40) cites Section 5.7, Theorem 2.3 of Lehmann's Testing Statistical Hypotheses (1959).
- ^ Non-statisticians may be confused because another F-test is nonrobust: When used to test the equality of the variances of two populations, the F-test is unreliable if there are deviations from normality (Lindman, 1974 ).
Notes
- ^ (Hinkelmann and Kempthorne (2008)
- ^ Hinkelmann and Kempthorne (2008)
- ^ Moore and McCabe )
- ^ Anscombe (1948)
- ^ Kempthorne and Cox, Chapter 2
- ^ Hinkelmann and Kempthorne (2008, Chapters 5-6)
- ^ Hinkelmann and Kempthorne (2008, Chapter 7 or 8)
- ^ Cox, Chapter 2
- ^ Bailey (2008)
- ^ (Hinkelmann and Kempthorne 2008, volume one, chapter 7
- ^ Bailey chapter 1.14)
- ^ Freedman
- ^ Pierce, Block & Aguinis (2004, p. 918)
- ^ Levine & Hullett (2002)
- ^ Bortz, 1999, p. 269f.;
- ^ Bühner & Ziegler (2009, p. 413f)
- ^ a b Tabachnick & Fidell (2007, p. 55)
- ^ a b Olejnik, S. & Algina, J. 2003. Generalized Eta and Omega Squared Statistics: Measures of Effect Size for Some Common Research Designs Psychological Methods. 8:(4)434-447. http://cps.nova.edu/marker/olejnik2003.pdf
- ^ Zhang (2011)
- ^ Gosset (1908)
- ^ The Correlation Between Relatives on the Supposition of Mendelian Inheritance. Ronald A. Fisher. Philosophical Transactions of the Royal Society of Edinburgh. 1918. (volume 52, pages 399–433)
- ^ On the "Probable Error" of a Coefficient of Correlation Deduced from a Small Sample. Ronald A. Fisher. Metron, 1: 3-32 (1921)
References
- Anscombe, F. J. (1948). "The Validity of Comparative Experiments". Journal of the Royal Statistical Society. Series A (General) 111 (3): 181–211. doi:10.2307/2984159. JSTOR 2984159. MR30181.
- Bailey, R. A. (2008). Design of Comparative Experiments. Cambridge University Press. ISBN 978-0-521-68357-9. http://www.maths.qmul.ac.uk/~rab/DOEbook. Pre-publication chapters are available on-line.
- Caliński, Tadeusz & Kageyama, Sanpei (2000). Block designs: A Randomization approach, Volume I: Analysis. Lecture Notes in Statistics. 150. New York: Springer-Verlag. ISBN 0-387-98578-6.
- Christensen, Ronald (2002). Plane Answers to Complex Questions: The Theory of Linear Models (Third ed.). New York: Springer. ISBN 0-387-95361-2.
- Cohen, Jacob (1992). "Statistics a power primer". Psychology Bulletin 112: 155–159. doi:10.1037/0033-2909.112.1.155. PMID 19565683.
- Cohen, Jacob (1988). Statistical power analysis for the behavior sciences (2nd ed.).
- Cox, David R. (1958). Planning of experiments
- Cox, David R. & Reid, Nancy M. (2000). The theory of design of experiments. (Chapman & Hall/CRC).
- Fisher, Ronald (1918). "Studies in Crop Variation. I. An examination of the yield of dressed grain from Broadbalk". Journal of Agricultural Science 11: 107–135. http://www.library.adelaide.edu.au/digitised/fisher/15.pdf.
- Freedman, David A. et al. Statistics, 4th edition (W.W. Norton & Company, 2007) [1]
- Freedman, David A.(2005). Statistical Models: Theory and Practice, Cambridge University Press. ISBN=9780521671057
- Hettmansperger, T. P.; McKean, J. W. (1998). Robust nonparametric statistical methods. Kendall's Library of Statistics. 5 (First ed.). London: Edward Arnold. pp. xiv+467 pp.. ISBN 0-340-54937-8, 0-471-19479-4. MR1604954. }
- Hinkelmann, Klaus & Kempthorne, Oscar (2008). Design and Analysis of Experiments. I and II (Second ed.). Wiley. ISBN 978-0-470-38551-7.
- Olejnik, Stephen & Algina, James (2003). "Generalized Eta and Omega Squared Statistics: Measures of Effect Size for Some Common Research Designs". Psychological Methods 8 (4): 434–447. doi:10.1037/1082-989X.8.4.434. PMID 14664681. http://cps.nova.edu/marker/olejnik2003.pdf.
- Kempthorne, Oscar (1979). The Design and Analysis of Experiments (Corrected reprint of (1952) Wiley ed.). Robert E. Krieger. ISBN 0-88275-105-0.
- Lentner, Marvin; Thomas Bishop (1993). Experimental design and analysis (Second ed.). P.O. Box 884, Blacksburg, VA 24063: Valley Book Company. ISBN 0-9616255-2-X.
- Levine, T. R. & Hullett, C. R. (2002). "Eta-squared, partial eta-squared, and misreporting of effect size in communication research". Human Communication Research, 28, 612-625.
- Lindman, H. R. (1974). Analysis of variance in complex experimental designs. San Francisco: W. H. Freeman & Co. Hillsdale, NJ USA: Erlbaum.
- Rosenbaum, Paul R. (2002). Observational Studies (2nd ed.). New York: Springer-Verlag.
- Tabachnick, Barbara G. & Fidell, Linda S. (2007). Using Multivariate Statistics (5th ed.). Boston: Pearson International Edition.
- Wichura, Michael J. (2006). The coordinate-free approach to linear models. Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge: Cambridge University Press. pp. xiv+199. ISBN 978-0-521-86842-6, ISBN 0-521-86842-4. MR2283455.
- Zhang XHD (2011). Optimal High-Throughput Screening: Practical Experimental Design and Data Analysis for Genome-scale RNAi Research. Cambridge University Press. ISBN 978-0-521-73444-8.
External links
- SOCR ANOVA Activity and interactive applet.
- One-Way and Two-Way ANOVA in QtiPlot
- Examples of all ANOVA and ANCOVA models with up to three treatment factors, including randomized block, split plot, repeated measures, and Latin squares
- NIST/SEMATECH e-Handbook of Statistical Methods, section 7.4.3: "Are the means equal?"
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||